Самая быстрая логика LLM, основанная на диффузии
Сегодня мы представляем Mercury 2 — самую быструю в мире модель логического языка, созданную для того, чтобы производственный искусственный интеллект казался немедленным.
Почему сейчас скорость имеет большее значение?
Производственный ИИ больше не является подсказкой и ответом. В этот цикл входят агент, конвейер восстановления и задачи извлечения, выполняющиеся на томе в фоновом режиме. В циклах задержка не видна ни разу. Это усугубляется на каждом этапе, с каждым пользователем, с каждой повторной попыткой.
Однако нынешние LLM по-прежнему сталкиваются с тем же препятствием: авторегрессионное последовательное декодирование. По одному жетону, слева направо.
Новый фундамент: распространение логики реального времени
Меркурий 2 не декодирует последовательно. Он генерирует ответы посредством параллельного уточнения, одновременно генерируя несколько токенов и конвертируя их за меньшее количество шагов. Меньше пишущих машинок, больше редакторов, редактирующих полные черновики одновременно. Результат: более чем в 5 раз более быстрая генерация с принципиально другой кривой скорости.
Это преимущество в скорости также меняет аргумент. Сегодня более высокий интеллект означает больше вычислений во время тестирования — более длинные цепочки, больше выборок, больше повторных попыток — за счет прямых затрат на задержку и стоимость. Логика, основанная на распространении, обеспечивает качество логического уровня в пределах бюджета задержки в реальном времени.
Меркурий 2 с первого взгляда
«Меркурий-2» меняет кривую качества и скорости развертывания производства:
-
шаг: 1009 токенов в секунду на графическом процессоре NVIDIA Blackwell
-
цена: 0,25 доллара США/1 миллион входных токенов 0,75 доллара США/1 миллион выходных токенов
-
качество: Конкурентоспособен ведущим моделям, оптимизированным по скорости.
-
функции: Настраиваемая логика · 128 тыс. ссылок · Использование собственных устройств · Выравнивание по схеме вывода JSON

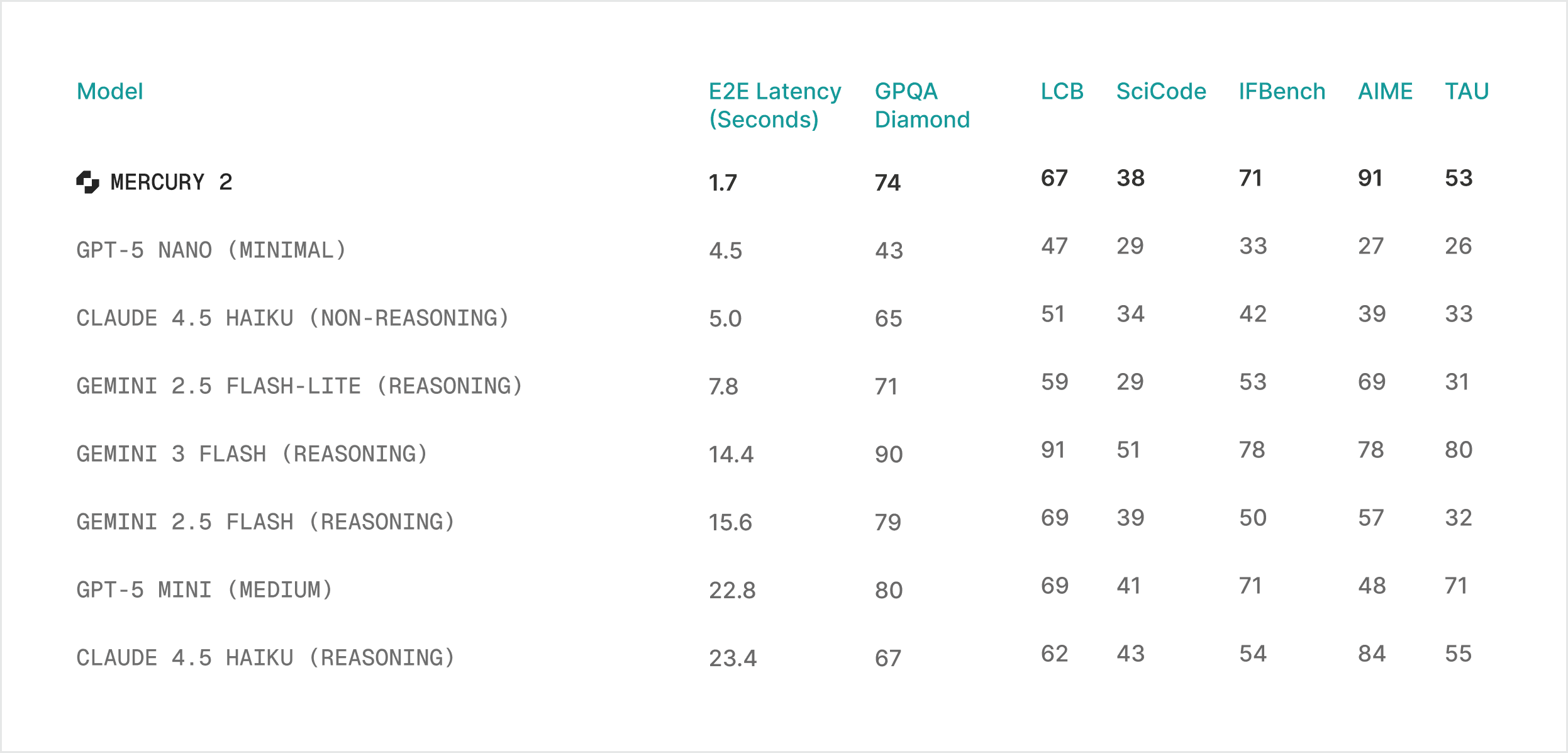
Мы оптимизируем скорость, которую фактически испытывают пользователи: оперативность в те моменты, когда пользователи сталкиваются с ними — низкая задержка p95 при высокой параллельной работе, стабильное межповоротное поведение и стабильная пропускная способность, когда система занята.
«Mercury 2 от Inception демонстрирует, что возможно, когда архитектура новой модели соответствует инфраструктуре искусственного интеллекта NVIDIA. Превышение 1000 токенов в секунду на графических процессорах NVIDIA подчеркивает производительность, масштабируемость и универсальность нашей платформы для поддержки всего спектра рабочих нагрузок искусственного интеллекта».
Шрути Копаркар, старший менеджер по продуктам группы ускоренных вычислений NVIDIA
Что открывает «Меркурий 2» в производстве
Mercury 2 превосходно работает в приложениях, чувствительных к задержке, где удобство работы пользователя не может быть поставлено под угрозу.
1. Кодирование и редактирование
Автозаполнение, предложения следующего редактирования, рефакторинг, интерактивные агенты кода — рабочие процессы, в которых разработчик находится в курсе, и любая пауза прерывает поток.
«Предложения приходят так быстро, что кажется, что это часть вашего собственного мышления, а не то, чего вам нужно ждать».
Макс Брунсфельд, соучредитель Z
2. Агентский цикл
Рабочий процесс агента выполняет серию из десятков вызовов оценки для каждой задачи. Уменьшение задержки на вызов не только экономит время, но также меняет количество шагов, которые вы можете предпринять, и качество конечного результата.
«Теперь мы используем новейшие модели Mercury для интеллектуальной оптимизации проведения кампаний в масштабе. Используя аналитику в реальном времени и динамически улучшая доставку, мы добиваемся более высокой производительности, большей эффективности и более гибкой рекламной экосистемы на базе искусственного интеллекта. Это достижение укрепляет нашу приверженность автономной рекламе, где интеллектуальные системы постоянно совершенствуют исполнение, чтобы обеспечить измеримые результаты для наших клиентов».
Адриан Витас, старший вице-президент, главный архитектор, Viant
«Мы оцениваем Mercury 2 из-за его непревзойденной задержки и качества, что особенно ценно для очистки стенограммы в реальном времени и интерактивных приложений HCI. Ни одна другая модель не может приблизиться к скорости, которую может обеспечить Mercury!»
Сахадж Гарг, технический директор и соучредитель Vispr Flow
«Mercury 2 как минимум в два раза быстрее GPT-5.2, и это меняет для нас правила игры».
Сучинтан Сингх, технический директор и соучредитель Skywarn
3. Голос и разговор в реальном времени
Голосовые интерфейсы имеют самый ограниченный бюджет задержки среди искусственного интеллекта. Mercury 2 обеспечивает качество логического уровня в естественном речевом ритме.
«Мы создаем реалистичные видео-аватары с искусственным интеллектом, которые взаимодействуют в реальном времени с реальными людьми, поэтому низкая задержка — это не хорошо, это все. Меркурий 2 стал большим открытием в нашем голосовом стеке: быстрое, последовательное генерирование текста, которое делает весь процесс естественным и человечным».
Макс Сапо, генеральный директор и соучредитель Happyverse AI
«Качество Mercury 2 превосходное, а низкая задержка модели позволяет более оперативно реагировать на голосовые агенты».
Оливер Сильверстайн, генеральный директор и соучредитель OpenCall
4. ПОИСК И Тряпочный трубопровод
Задержки при многоскачковом извлечении, переранжировании и суммировании увеличиваются в геометрической прогрессии. Mercury 2 позволяет добавлять логику в цикл поиска, не тратя бюджет на задержку.
«Наше партнерство с Inception делает искусственный интеллект в реальном времени практичным для нашего поискового продукта. Каждый клиент SearchBlocks, в вопросах поддержки клиентов, соответствия требованиям, рисков, аналитики и электронной коммерции, получает выгоду от анализа всех своих данных за доли секунды».
Тимо Сельварадж, директор по продукту, SearchBlocks
начать
Меркурий 2 уже доступен.
-
Запросить ранний доступ
-
Попробуйте Mercury 2 в чате
Mercury 2 совместим с OpenAI API. Вставьте в существующий стек — переписывание не требуется.
Если вы проводите оценку предприятия, мы будем сотрудничать с вами в вопросах соответствия рабочей нагрузки, разработки оценки и проверки производительности с учетом ожидаемых вами ограничений обслуживания.
