: Overparameterization, Generalizability, and SAM
The dramatic success of modern deep learning — especially in the domains of Computer Vision and Natural Language Processing — is built on “overparameterized” models: models with more than enough parameters to memorize the training data perfectly. Functionally, a model can be diagnosed as overparameterized when it can easily achieve a near-perfect training accuracy (close to 100%) with near-zero training loss for a given task.
However, the usefulness of such a model depends on whether it performs well on the held-out test data drawn from the same distribution as the training set, but unseen during training. This property is called “generalizability” — the ability of a model to maintain performance on new examples — and it is essential for any deep learning model to be practically useful.
Classical Machine Learning theory tells us that overparameterized models should catastrophically overfit and therefore generalize poorly. However, one of the most surprising discoveries of the past decade is that models in this class often generalize remarkably well.
This highly counterintuitive phenomenon has been investigated in a series of papers, starting with the seminal works of Belkin et al. (2018) and Nakkiran et al. (2019), which demonstrated that there exists a “double descent” curve for generalizability: as model size increases, generalization first worsens (as classical theory predicts), then improves again beyond a critical threshold — provided the model is trained with the appropriate optimization methods.

Figure 1 shows a cartoon of a double descent curve. The y-axis plots test error — a measure of generalizability, where lower error indicates better generalization — while the x-axis shows the number of model parameters. As model size increases, training error (dashed blue line) rapidly approaches zero, as expected.
The test error (solid blue line) exhibits a more interesting behavior: it initially decreases with model size — the first descent, highlighted by the left red circle — and then rises to a peak at the interpolation threshold marked by the vertical dashed line, where the model has the worst generalization. Beyond this threshold, however, in the overparameterized regime, the test error decreases again — the second descent, highlighted by the right red circle — and continues to decline as more parameters are added. This is the regime of interest for modern deep learning models.
In Machine Learning, one finds the parameters of a model by minimizing a loss function on the training dataset. But does simply minimizing our favorite loss function — like cross-entropy — on the training dataset guarantee satisfactory generalization properties for the class of overparametrized models? The answer is — generally speaking — no! Whether one is interested in fine-tuning a pre-trained model or training a model from scratch, it is important to optimize your training algorithm to ensure that you have a sufficiently generalizable model. This is what makes the choice of the optimizer a crucial design choice.
Sharpness-Aware-Minimization (SAM) — introduced in a paper by Foret et al. (2019) — is an optimizer designed to improve generalizability of an overparameterized model. In this article, I present a pedagogical review of SAM that includes:
- An intuitive understanding of how SAM works and why it improves generalization.
- A deep dive into the algorithm, explaining the key mathematical steps involved.
- A PyTorch implementation of the optimizer class in a training loop, including an important caveat for models with BatchNorm layers.
- A quick demonstration of the effectiveness of the optimizer in improving generalization on an image classification task with a ResNet-18 model.
The complete code used in this article can be found in this Github repo — feel free to play around with it!
The Notion of Sharpness
To begin with, let us try to get an intuitive sense of why simply minimizing the loss function may not be enough for optimal generalization.
A useful picture to have in mind is that of the loss landscape. For a large overparametrized model, the loss landscape has multiple local and global minima. The local geometries around such minima can vary significantly along the landscape. For example, two minima may have nearly identical loss values, yet differ dramatically in their local geometry: one may be sharp (narrow valley) while the other is flat (wide valley).
One formal measure for comparing these local geometries is “sharpness”. At any given point w in the loss landscape with loss function L(w), sharpness S(w) is defined as:

Let me unpack the definition. Imagine you are at a point w in the loss landscape and you perturb the parameters such that the new parameter always lies inside a ball of radius ρ with center w. Sharpness is then defined as the maximal change in the loss function within this family of perturbations. In the literature, it is also referred to as the worst-direction sharpness for obvious reasons.
One can readily see that for a sharp minimum — a steep, narrow valley — the value of the loss function will change dramatically with small perturbations in certain directions and lead to a high value for sharpness. For a flat minimum on the other hand — a wide valley — the value of loss function will change relatively slowly with small perturbations and lead to a lower value for sharpness. Therefore, sharpness gives a measure of flatness for a given minimum in the loss landscape.
There exists a deep connection between the local geometry of a minimum — especially the sharpness measure— and the generalization property of the resultant model. Over the last decade, a significant amount of theoretical and empirical research has gone into clarifying this connection. For instance — as the paper by Keskar et al. (2016) points out — global minima with similar values of the loss function can have significantly different generalization properties depending on their sharpness measures.
The basic lesson that seems to be emerge from these studies is: flatter (less sharp) minima are positively correlated with better generalization of models. In particular, the model should avoid getting stuck in a sharp minima during training if it has to generalize well. Therefore, for training a model with good generalization, one needs to ensure that the optimization procedure not only minimizes the loss function but also seeks to maximize the flatness (or equivalently minimize the sharpness) of the minima.
This is precisely the problem that the SAM optimizer is designed to solve, and this is what we turn to in the next section.
A quick aside: note that the above picture gives a conceptual explanation of why an overparameterized model can potentially avoid the problem of overfitting. It is because a large model has a rich loss landscape which provides a multiplicity of flat global minima with excellent generalization properties.
The Sharpness-Aware Minimization (SAM) Algorithm
Let us recall the standard optimization of a model. It involves finding model parameters that minimize a given loss function computed over a mini-batch B. At every time-step, one computes the gradient of the loss with respect to the parameters, and updates the parameters according to the rule:

Unlike SGD or Adam, SAM does not minimize L directly. Instead, at a given point in the loss landscape, it first scans its neighborhood of a given size ρ and finds the perturbation that maximizes the loss function. In the second step, it minimizes this maximum loss function. This allows the optimizer to find parameters that lie in neighborhoods with uniformly low loss value, which results in smaller sharpness values and flatter minima.
Let’s discuss the procedure in a little more detail. The loss function for the SAM optimizer is:
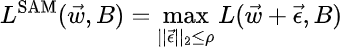
where ρ denotes the upper bound on the size of the perturbations. The perturbation that maximizes the function L (often called adversarial perturbation since it maximizes the conventional loss) can be found by noting that:
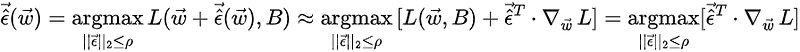
where the second equality is an approximation obtained by Taylor-expanding the perturbed function in the first step, and the last equality follows from the ϵ-independence of the first term in square brackets in the previous step. This last equality can be solved for the adversarial perturbation as follows:

Plugging this back in the equation for the SAM loss, one can compute the gradients of the SAM loss to the leading order in derivatives of ϵ:

This is the most crucial equation for the optimization procedure. To the leading order in derivatives of ϵ, the gradients of the SAM loss function can be approximated by the gradients of the conventional loss function evaluated at the adversarially perturbed point. Using the above formula for the gradients, one can now execute the standard optimizer step:

This completes one full SAM iteration. Next, let us translate the algorithm from English to PyTorch.
PyTorch Implementation in a Training Loop
An illustrative example of a training loop with a SAM optimizer is given in the code block sam_training_loop.py. For concreteness, we have chosen a generic image classification problem, but the same structure broadly holds for a wide range of Computer Vision and NLP tasks. The SAM optimizer class is shown in the code block sam_optimizer_class.py.
Note that defining a SAM optimizer requires specifying two pieces of data:
- A base optimizer (like SGD or Adam), since SAM involves a standard optimizer step in the end.
- A hyperparameter ρ, which puts an upper bound on the size of the admissible perturbations.
A single iteration of the optimizer involves two forward passes and two backward passes. Let’s trace out the key steps of the code in sam_training_loop.py:
- Line 5 computes the loss function L(w, B) for the current mini-batch B — the first forward pass.
- Line 6 computes the gradients of the loss function L(w, B) — the first backward pass.
- Line 7 calls the function sam_optimizer.first_step from the SAM optimizer class (see below) that computes the adversarial perturbation using the formula discussed above, and perturbs the weights of the model as discussed before.
- Line 10 computes the loss function for the perturbed model — the second forward pass.
- Line 11 computes the gradients of the loss function for the perturbed model— the second backward pass.
- Line 12 calls the function sam_optimizer.second_step from the optimizer class (see below) that restores the weights to w_t and then uses the base optimizer to update the weights w_t using the gradients computed at the perturbed point.
A Caveat: SAM with BatchNorm
There is an important point that one needs to keep in mind while deploying SAM in a training loop if the model has any module that includes batch-normalization layers. During training, BatchNorm implements the normalization using the current batch statistics and updates the running statistics at every forward pass. For evaluation, it uses the running statistics.
Now, as we saw above, SAM involves two forward passes per iteration. For the first pass, BatchNorm works in the standard fashion. During the second pass, however, we are using perturbed weights to compute loss, and the naive training function in the code block sam_training_loop.py will allow the BatchNorm layers to update the running statistics during the second pass as well. This is undesirable because the running statistics should only reflect the behavior of the original model, not the perturbed model which is only an intermediate step for computing gradients. Therefore, one has to explicitly disable the running statistics update during the second pass and enable it before the next iteration.
For this purpose, we will use two explicit functions disable_bn_stats and enable_bn_stats in the training loop — simple examples of such functions are shown in code block running_stat.py — they toggle the track_running_stats parameter (line 4 and line 9) of BatchNorm function in PyTorch. The modified training loop is given in the code block mod_train.py.
Demo: Image classification with ResNet-18
Finally, let’s demonstrate how the SAM optimization improves the generalization of a model in a concrete example. We will consider an image classification problem using the Fashion-MNIST dataset (MIT License): it consists of 60,000 training images and 10,000 testing images across 10 distinct, mutually exclusive classes, where each image is grayscale with 28*28 pixels.
As the classifier model, we will choose a PreAct ResNet-18 without any pre-training. While a discussion on the precise ResNet-18 architecture is not very relevant for our purpose, let us recall that the model consists of a sequence of building blocks, each of which is made up of convolutional layers, BatchNorm layers, ReLU activation with skipped connections. The PreAct (pre-activation) indicates that the activation function (ReLU) comes before the convolutional layer in each block. For a standard ResNet-18, it is the other way round. I would refer the reader to the paper — He et al. (2015) — for more details on the architecture.
What is important to note, however, is that this model has about 11.2 million parameters, and therefore from the perspective of classical Machine Learning, it is an overparameterized model with the parameter-to-sample ratio being about 186:1. Also, since the model includes BatchNorm layers, we have to be careful about disabling the running statistics for the second pass, while using SAM.
We are now ready to carry out the following experiment. We train the model on the Fashion-MNIST dataset with the standard SGD optimizer first and then with the SAM optimizer using the same SGD as the base optimizer. We will consider a simple setup with a fixed learning rate lr=0.05 and with the momentum and the weight-decay both set to zero. The hyperparameter ρ in SAM is set to 0.05. All runs are performed on a single A100 GPU.
Since each SAM weight update requires two backpropagation steps — one to compute the perturbations and another to compute the final gradients — for a fair comparison each non-SAM training run must execute twice as many epochs as each SAM training run. We will therefore have to compare a metric from one epoch of SAM training run to a metric from two epochs of non-SAM training run. We will call this a “standardized epoch” and a metric recorded at standardized epochs will be labelled as metric_st. We will restrict the experiment to 150 standardized epochs, which means the SAM training runs for 150 epochs and the non-SAM training runs for 300 epochs. We will train the SAM-optimized model for an additional 50 epochs to get an idea of how the model behaves on longer training.
In trying to check which optimizer gives better generalization, we will compare the following two metrics after each standardized epoch of training:
- Test accuracy: Performance of the model on the test dataset.
- Generalizability gap: Difference between the training accuracy and test accuracy.
The test accuracy is an absolute measure of how well the model generalizes after a certain number of training epochs. The generalizability gap, on the other hand, is a diagnostic that tells you how much a model is overfitting at a given stage of training.
Let us begin by comparing the training_loss_st and training_accuracy_st graphs, as shown in Figure 3. The model with SGD reaches near-zero loss and close to 99% training accuracy within 150 epochs, as expected of an overparametrized model. It is evident that SAM trains slowly compared to SGD and takes more standardized epochs to reach a near-perfect training accuracy. This is evident from the fact that the training loss as well as the training accuracy continues to improve as one trains the SAM-optimized model for more epochs beyond the stipulated 150.

Test accuracy. The graphs in Figure 4 compares the test accuracies for the two cases after each standardized epoch.

The SGD-optimized model reaches 92% test accuracy around epoch 50 and plateaus around that value for the next 100 epochs. The SAM-optimized model generalizes poorly in the initial phase of the training — until around 80 epochs — as evident from the lower test accuracies in this phase compared to the SGD graph. However, around epoch 80, it catches up with the SGD graph and eventually surpasses it by a thin margin.
For this specific run, at the end of 150 epochs, the test accuracy for SAM stands at test_SAM = 92.5%, while that for SGD is test_SGD = 92.0%. Note that this is despite the fact that the SAM-trained model has a much lower training accuracy and training loss at this stage. If one trains the SAM-model for another 50 epochs, the test accuracy improves slightly to 92.7%.
Generalization Gap. The evolution of the generalization gap after each standardized epoch in course of the training process is shown in Figure 5.

The gap for the SGD model grows steadily with training and after 150 epochs reaches gap_SGD=6.8%, while for SAM it grows much more slowly and reaches gap_SAM= 2.3%. On further training for another 50 epochs, the gap for SAM climbs to around 3%, but it is still much lower compared to the SGD value.
While the difference in test accuracies is small between the two optimizers for the Fashion-MNIST dataset, there is a non-trivial difference in the generalization gaps, which demonstrates that optimizing with SAM leads to better generalization.
Concluding Remarks
In this article, I presented a pedagogical review of SAM as an optimizer that significantly improves the generalization of overparameterized deep learning models. We discussed the motivation and intuition behind SAM, walked through a step-by-step breakdown of the algorithm, and studied a simple example demonstrating its effectiveness compared to a standard SGD optimizer.
There are several interesting aspects of SAM that I didn’t have a chance to cover here. Let me briefly mention two of them. First, as a practical tool, SAM is particularly useful for fine-tuning pre-trained models on small datasets — something explored in detail by Foret et al.(2019) for CNN-type architectures and in many subsequent works for more general architectures. Second, since we opened our discussion with the connection between flat minima in the loss landscape and generalization, it is natural to ask whether a SAM-trained model — which demonstrably improves generalizability — does indeed converge to a flatter minimum. This is a non-trivial question, requiring a careful analysis of the Hessian spectrum of the trained model and a comparison with its SGD-trained counterpart. But that’s a story for another day!
Thanks for reading! If you have enjoyed the article, and would be interested to read more pedagogical articles on deep learning, do follow me on Medium and LinkedIn. Unless otherwise stated, all images and graphs used in this article were generated by the author.


